Method Overview
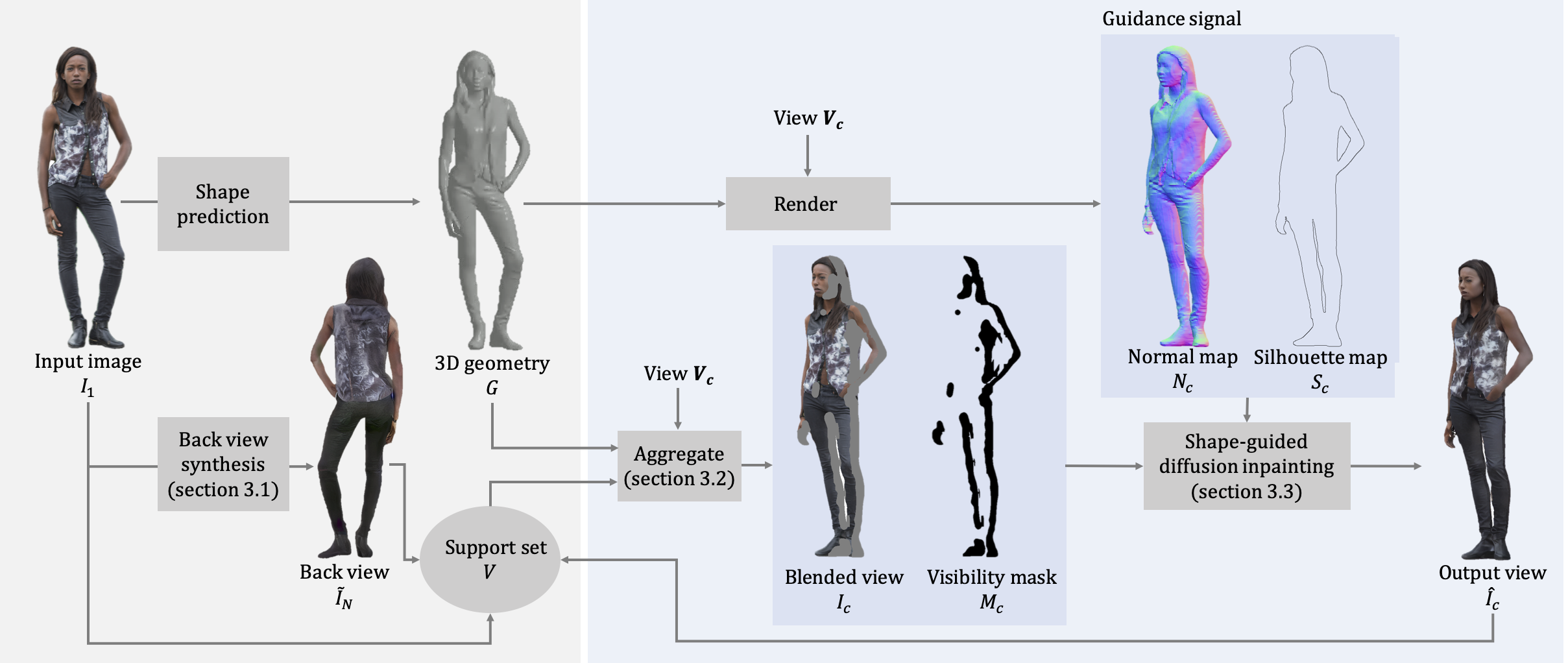
To generate a 360-degree view of a person from a single image, we first synthesize multi-view images of the person. We use off-the-shelf methods to infer the 3D geometry and synthesize an initial back-view of the person as a guidance. We add our input view and the synthesized initial back-view to our support set. To generate a new view, we aggregate all the visible pixels from our support set by blending their RGB color, weighted by visibility, viewing angles, and the distance to missing regions. To hallucinate the unseen appearance and synthesize view, we use a pretrained inpainting diffusion model guided by shape cues (normal and silhouette maps). We include the generated view in our support set and repeat this process for all the remaining views.
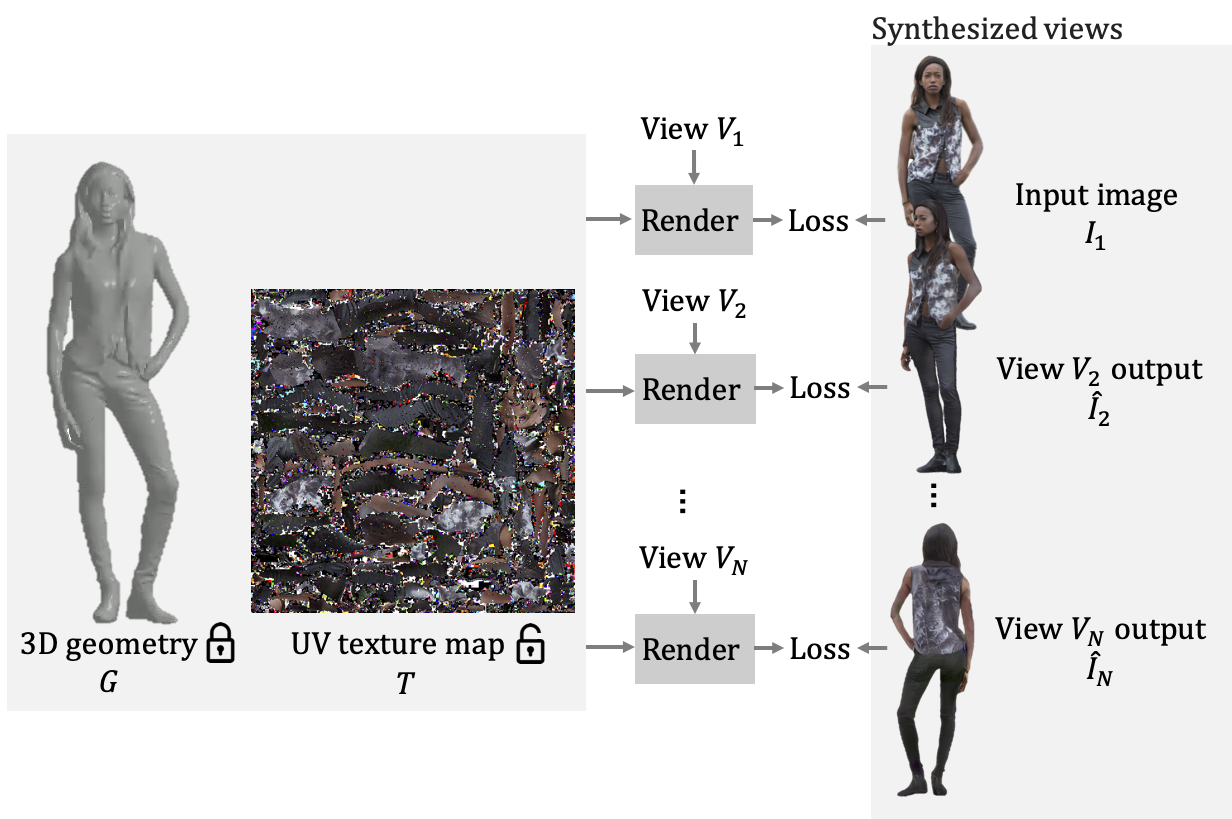
We then fuse these synthesized multi-view images to obtain a textured 3D human mesh. We use the computed UV parameterization to optimize a UV texture map with the geometry fixed. In each iteration, we differentiably render the UV texture map in every synthesized view from our set of views. We minimize the reconstruction loss between the rendered view and our synthesized view using both LPIPS loss and L1 loss. The fusion results in a textured mesh that can be rendered from any view.

















